
文本隐写(难度:EZ)
考验的是word的信息提取?反正没有那么恶心
首先,给了一个doc文件
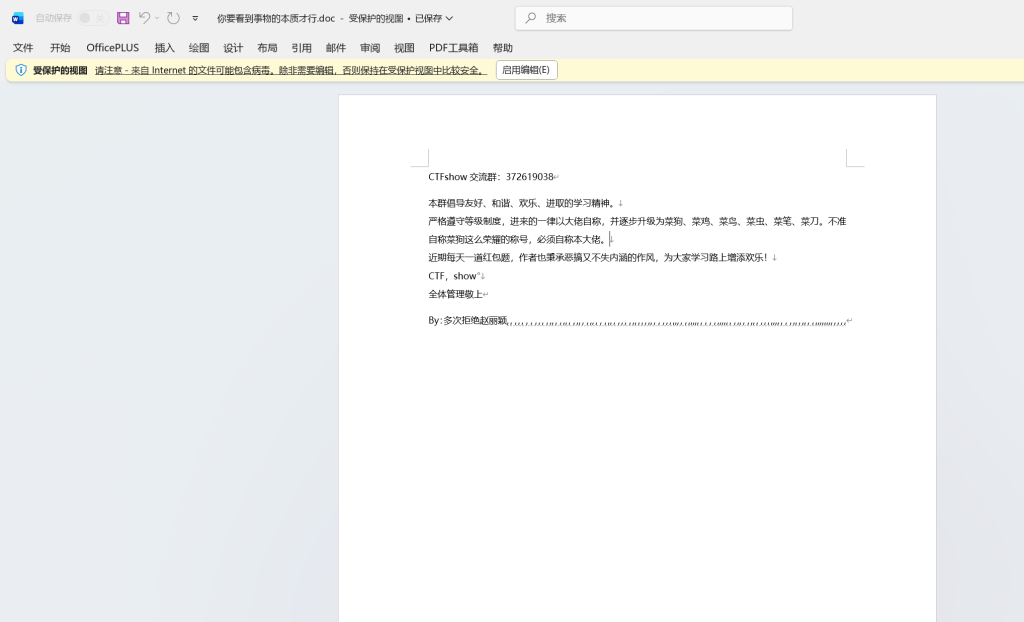
wps左上角 文件-->选项---》隐藏文字,可以看见如上的末尾逗号
ctrl+f 选择替换
将中文”,“替换为1
将英文“,”替换为0

得到01101111011001100110011001110011011001010011101000110000011110000011001100110100001110010011000000001010
复制01字符串到http://xiaoniutxt.com/binaryToString.html,
转化得到偏移量 3490
用010edit打开docx文件,寻址到3490 ctrl+g跳转(该文件101编辑器下有很多PK头)
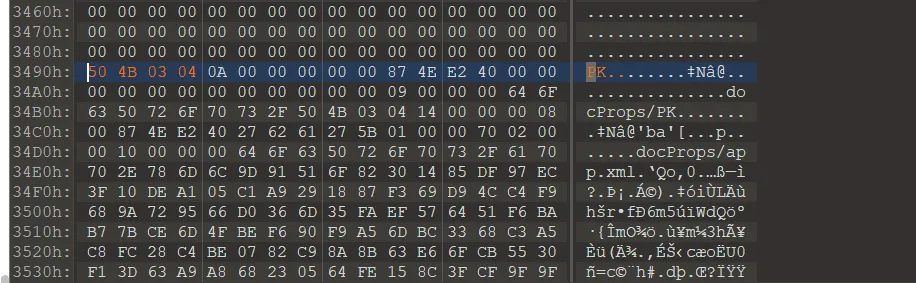
头:504b03040a
所以也需要将3490处的0000000xxxx0a 修改为504b03040a
(由于这一段后面没有新的504b03040a的头了)一直选中到末尾复制保存为新文件后缀为docx

继续修改隐藏文字,但是看不见(字体被设置成白色了),但是可以选中这段隐藏文字,通过“大声朗读”可以发现是一群字母,其中有R,于是通过查找方式看隐藏文字
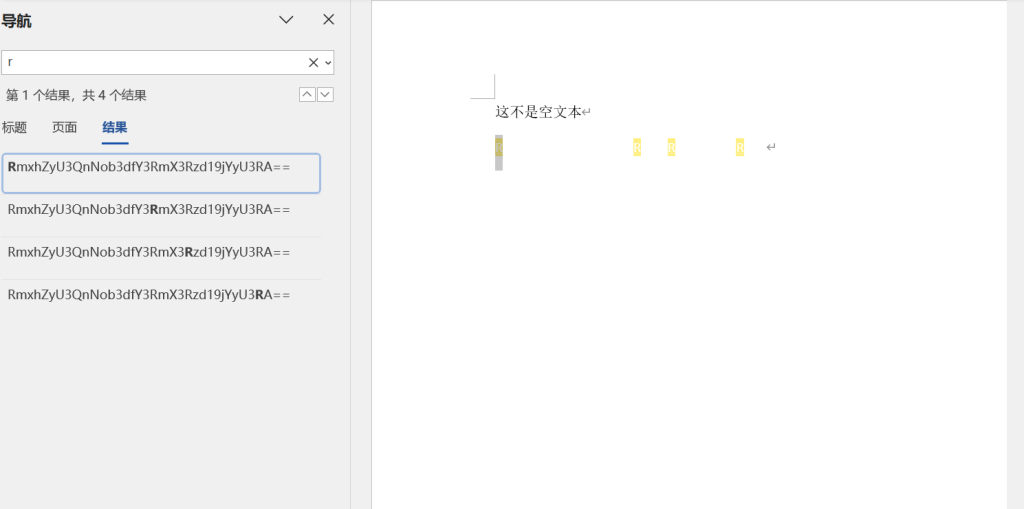
得到
RmxhZyU3QnNob3dfY3RmX3Rzd19jYyU3RA==
Base64解码得
Flag{show_ctf_tsw_cc}
miscx(难度:还行)
直接打开,发现只有两个文件,但是直接解压,会输出hint和flag两个隐藏的txt文件
选用bandzip打开
只打得开misc1.rar的png图片,其他全是加密的(看到图片右边可能有隐藏,想过可能需要改变png的16进制代码以完成分辨率和边界的扩展,但是用2020直接把另一个doc文件打开了)
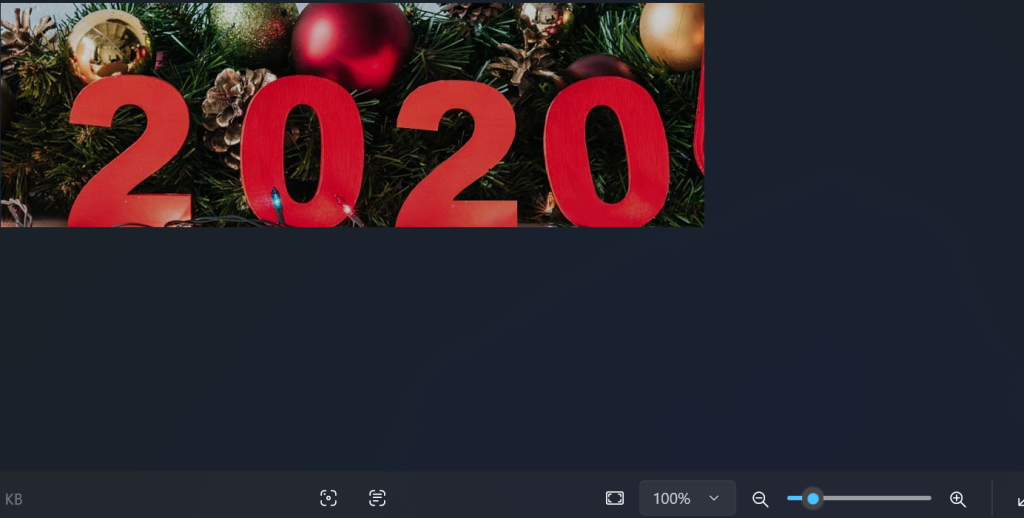
获得下面编码
♭‖♭‖‖♯♭♭♬‖♩♫‖♬∮♭♭¶♭‖♯‖¶♭♭‖∮‖‖♭‖§♭‖♬♪♭♯§‖‖♯‖‖♬‖‖♪‖‖♪‖¶§‖‖♬♭♯‖♭♯♪‖‖∮‖♬§♭‖‖‖♩♪‖‖♬♭♭♬‖♩♪‖♩¶‖♩♪‖♩♬‖¶§‖‖♩‖¶♫♭♭♩‖♬♯‖♬§♭‖♭‖♩¶‖‖∮♭♭♬‖‖♭‖♫§‖¶♫‖♩∮♭♭§‖♭§‖♭§§=在https://www.qqxiuzi.cn/bianma/wenbenjiami.php?s=yinyue进行音符解码得到
U2FsdGVkX1/eK2855m8HM4cTq8Fquqtm6QDbcUu4F1yQpA==尝试BaseX编码,发现都不是,看到有hint提示,猜测为rabit加密,key为2020
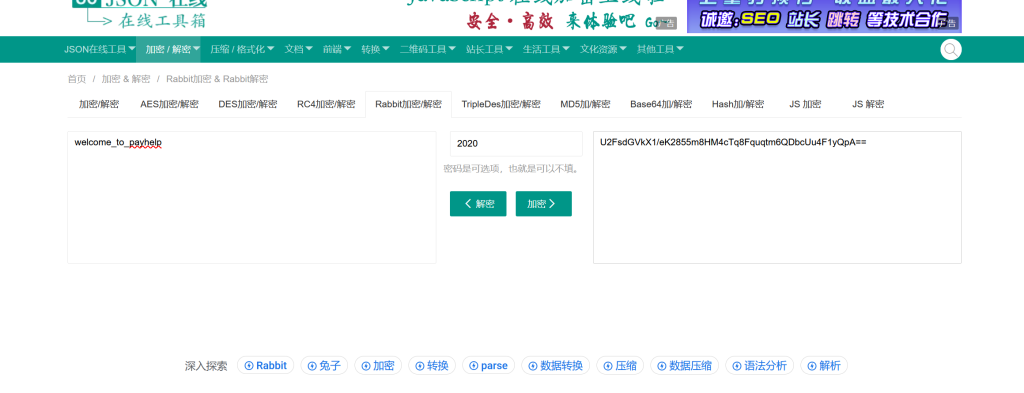
得到
welcome_to_payhelp发现是hint文件的密码
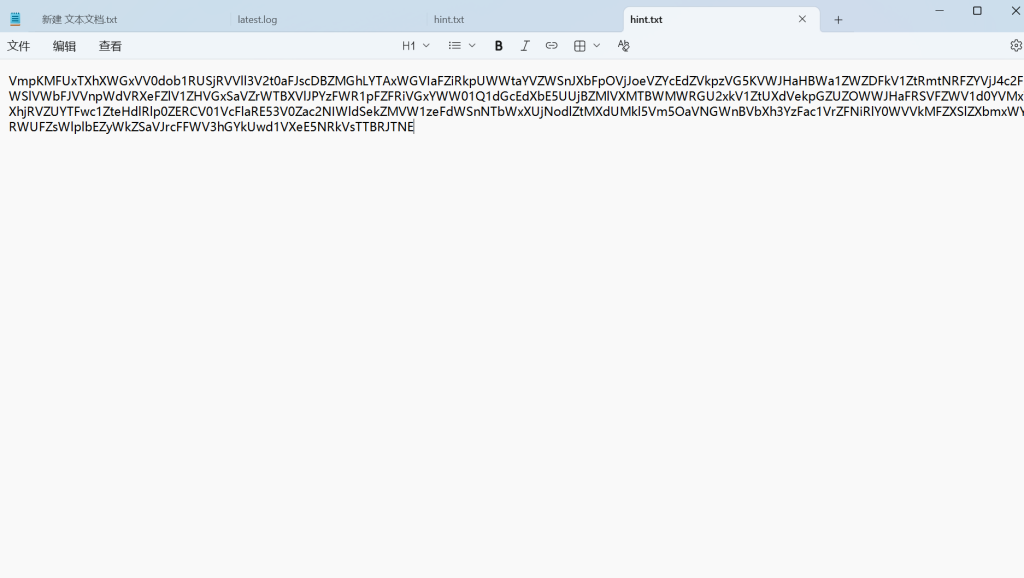
这串字符,尝试破解
大概经历了4、5次Base64解密
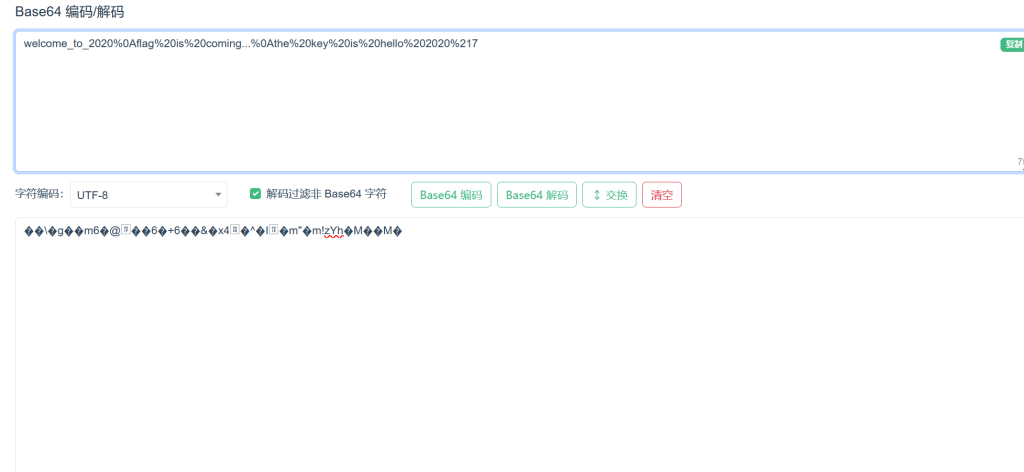
得到一个url编码,我懒得查表,直接ai
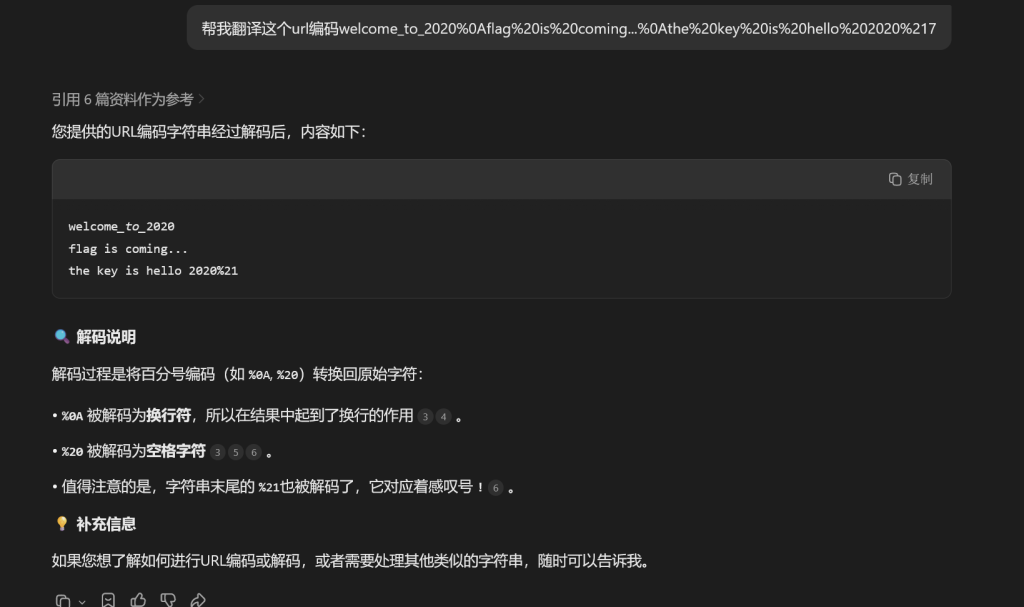
(%21是!,元宝没翻译出来)
获得flag.txt文件的密钥:hello 2020!,打开后获得flag{g00d_f0r_y0u}
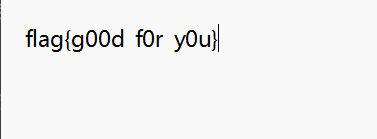
Misc50(难度:爆难TwT)
简言:压缩包套娃,然后密码转换,然后16进制解码得新的压缩包代码
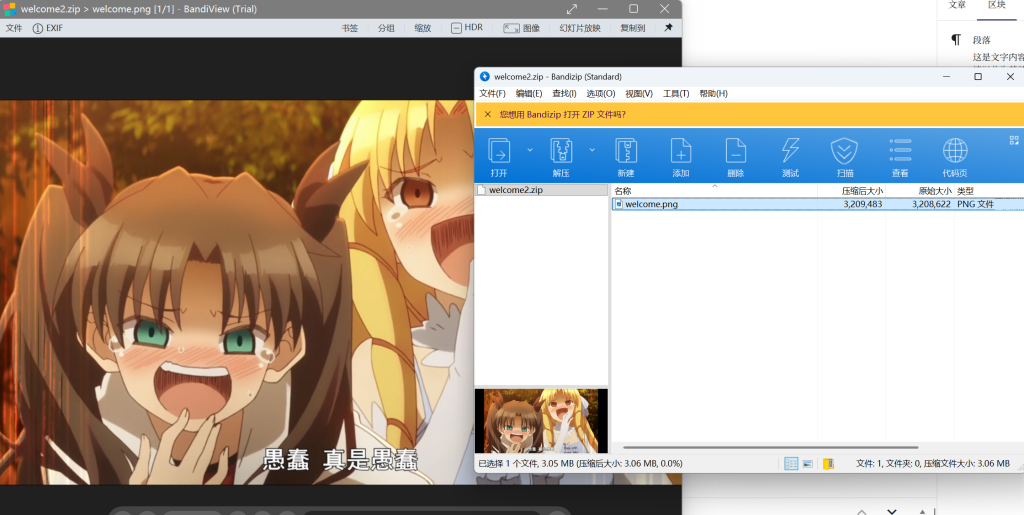
打开后只有一个图片,但是这个png大得夸张
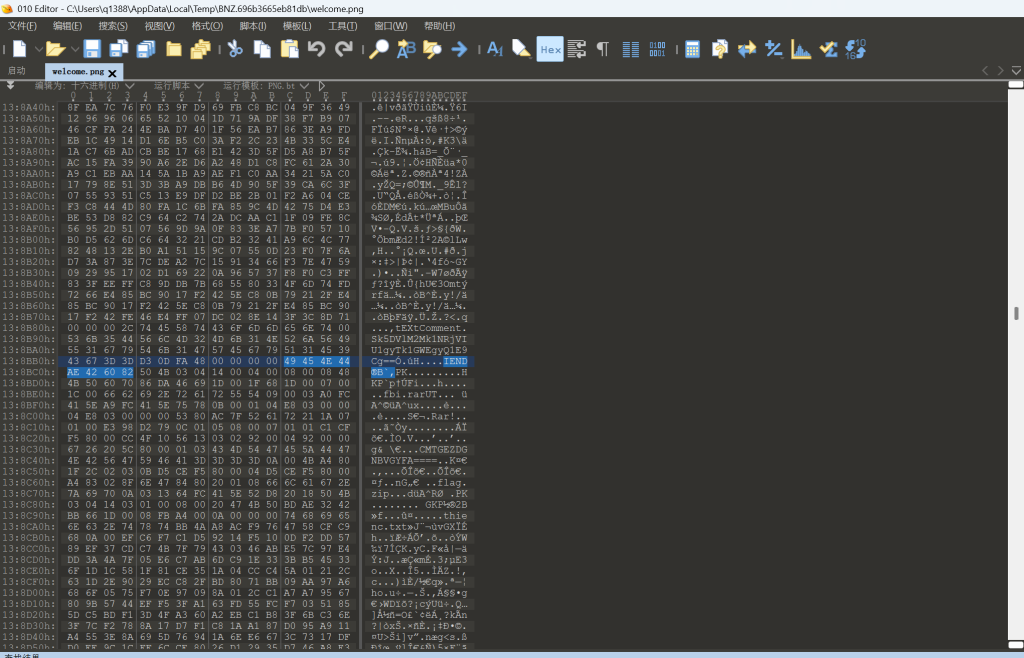
直接找到文件尾,把后面的zip文件单独抽出来,套娃:
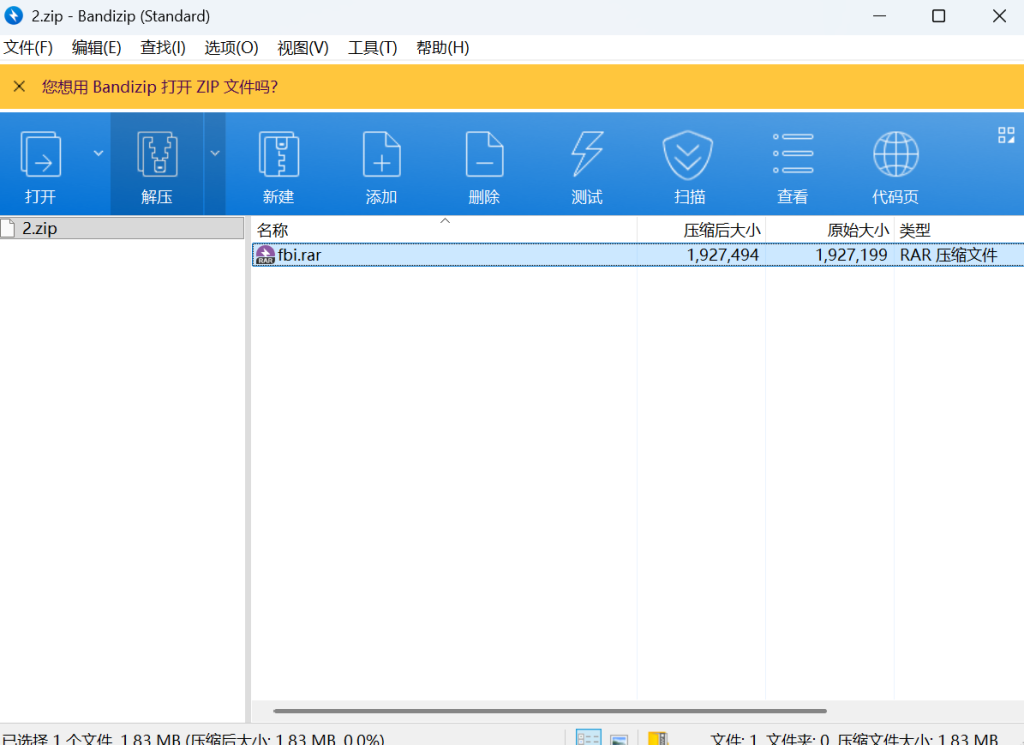
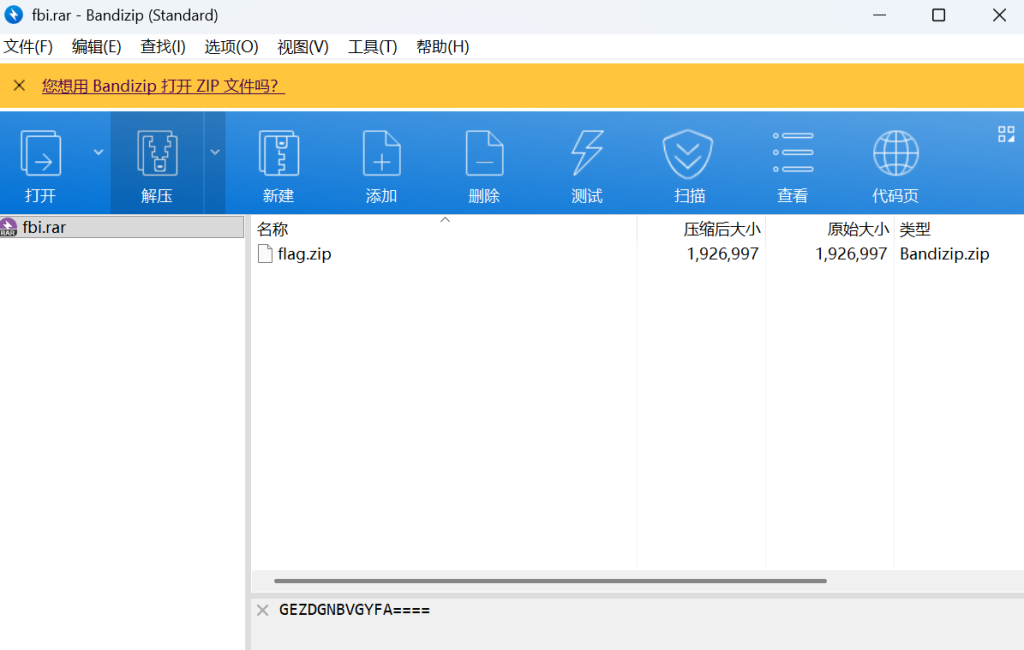
Bandzip用来查看层数和方向,退出来后发现最后一层压缩需要密码。
啥线索就没有了,想了半天,漏掉了一个线索,就是最开始分离图片时,末尾有一个“==”,这是Base解码[见上图]
tEXtComment Sk5DVlM2Mk1NRjVIU1gyTk1GWEgyQ1E9Cg==Sk5DVlM2Mk1NRjVIU1gyTk1GWEgyQ1E9Cg==过cyberchef(from base64)解码得JNCVS62MMF5HSX2NMFXH2CQ=
JNCVS62MMF5HSX2NMFXH2CQ=再过一遍cyberchef(from base32)解码得KEY{Lazy_Man}
除此之外!!!,老朋友7Z可以看rar文件注释,发现在第三层fbi.rar的注释里
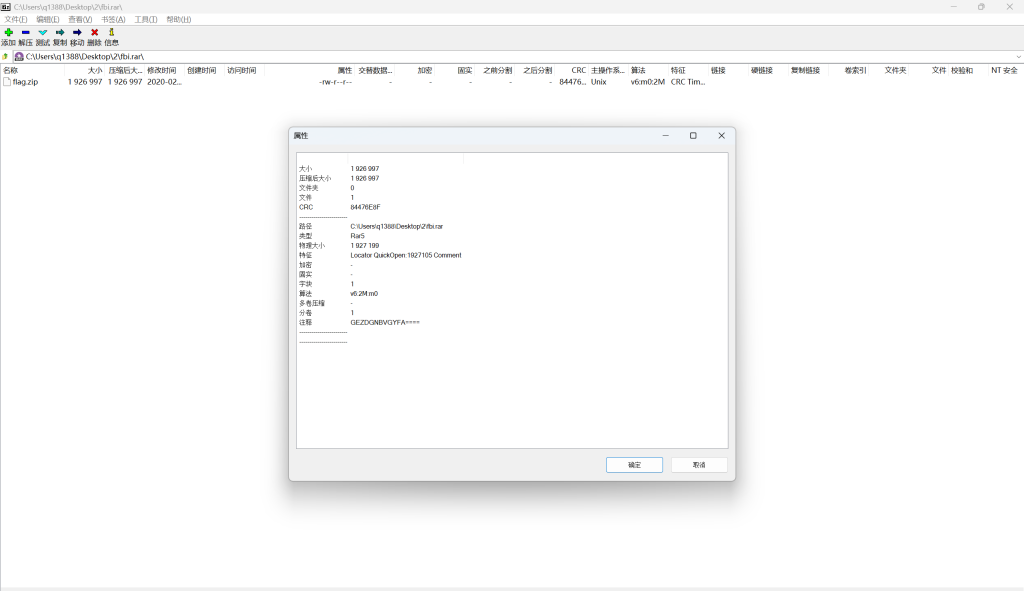
有一个Base编码GEZDGNBVGYFA====,过cyberchef(from base32)解码得123456
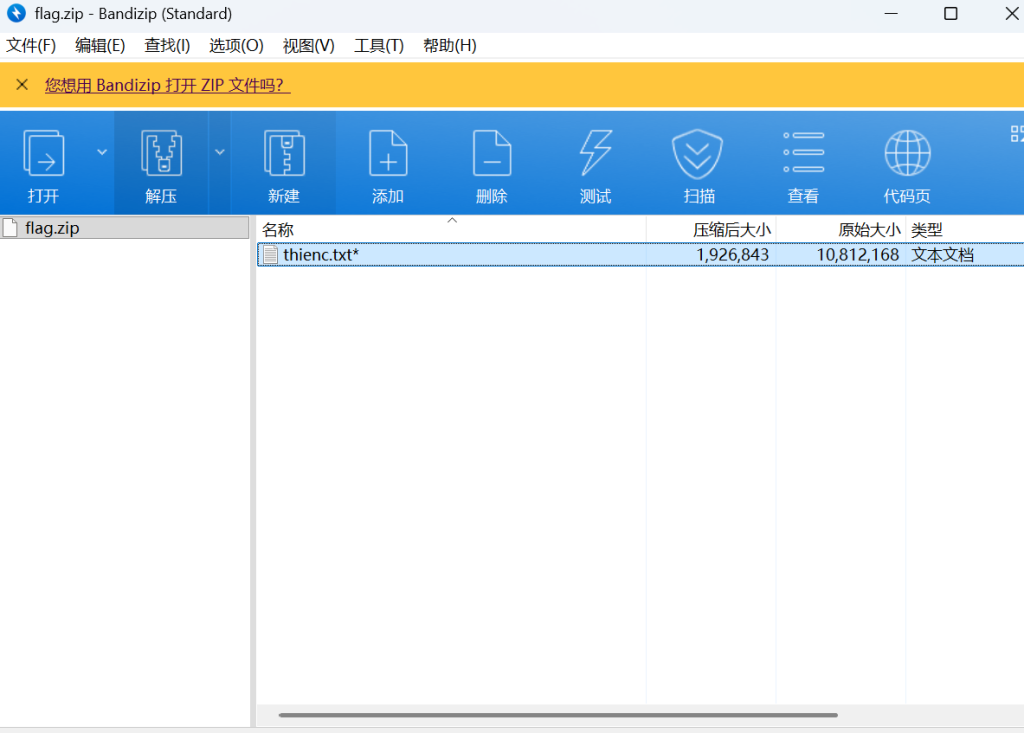
解压fbi.rar得flag.zip,有加密,尝试之前的KEY{Lazy_Man}和123456,123456能解密,得thienc.txt
得到了一串怪物,经观察,3078很长出现
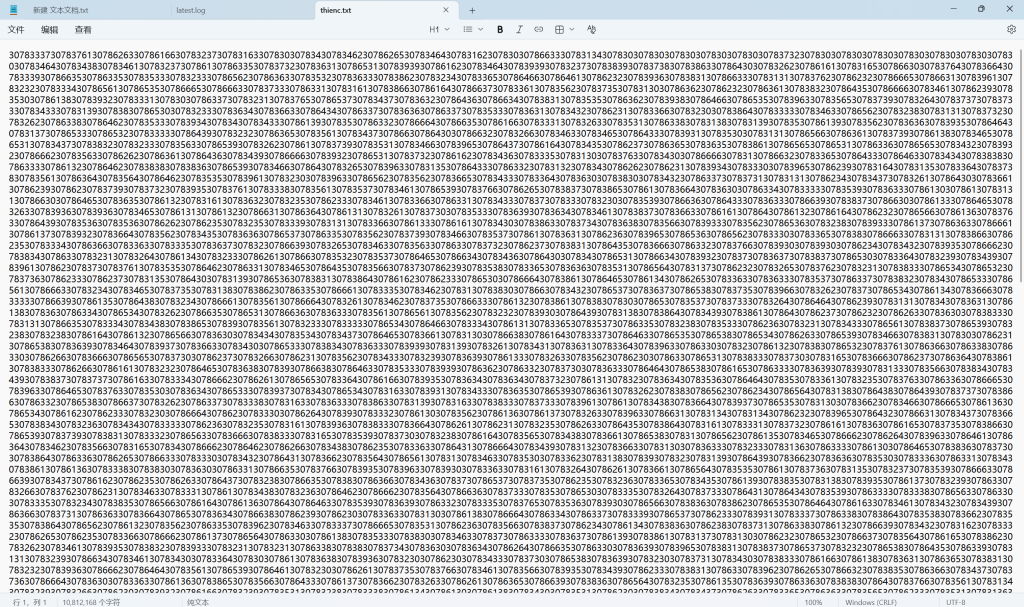
其中3078大量出现,用3078过cyberchef(from hex)得0x,
推测为16进制字符串转码,全文过python程序,解码16进制字符串
#这过程挺慢的
import re
from tqdm import tqdm
def read_file(filepath):
with open(filepath) as fp:
content=fp.read();
return content
number = read_file('thienc.txt')
result = []
result.append(re.findall(r'.{2}', number))
result = result[0]
strings =''
for i in tqdm(result, total=len(result), desc="处理中"):
y = bytearray.fromhex(i)
z = str(y)
z= re.findall("b'(.*?)'",z)[0]
strings += z
b= strings.split('0x')
strings=''
for i in b:
if len(i) ==1:
i= '0' + i
strings +=i
with open('te.txt', 'w') as f:
f.write(strings)发现是个7z文件
继续优化python程序,让解码出来的数据可以直接生成7Z压缩包
(太tm不容易了T_T好恶心的题)
7z压缩包,有加密
尝试之前的KEY{Lazy_Man}和123456,KEY{Lazy_Man}能解密,得secenc.txt,打开发现是base编码字符串
用secenc.txt里的字符串过cyberchef,经暴力穷举多次base解码(64-32-32-32-32-64-32-32-32-32-64-32-32-32-32)共15轮,得到具有明显规律的
!?字符串
将这段!?字符串放在word里,用空格替换回车(^p替换成 ),消除换行,使字符串成为规范的short ook编码,再将这段short ook编码解码成文本(Ook! to text),解码出来的文本为典型的Brainfuck编码
+++++ +++++ [->++ +++++ +++<] >++.+ +++++ .<+++ [->-- -<]>- -.+++ +++.<
++++[ ->+++ +<]>+ +++.< +++++ +[->- ----- <]>.< +++[- >+++< ]>+++ ++.++
+++++ .---- ----- .<+++ ++++[ ->--- ----< ]>--. <++++ +++[- >++++ +++<]
>++++ +++++ +++.- ----- --.-- ----. <++++ [->++ ++<]> +++++ .<+++ +++[-
>---- --<]> -.<++ ++[-> ++++< ]>.++ ++.<+ ++[-> ---<] >---- --.<+ +++[-
>++++ <]>++ .---- ---.< +++++ +[->- ----- <]>-- ----- -.<++ +++++ [->++
+++++ <]>++ ++.++ +++++ .++++ ++++. <++++ +++++ [->-- ----- --<]> -----
.<+++ +++++ +[->+ +++++ +++<] >++++ +++++ ++.<再将这段Brainfuck编码解码成文本:flag{Welc0me_tO_cTf_3how!}
Misc50(难度:EZZZZZ)


Comments 2 条评论
日更呢日更呢 没有日更我就要日你了哦`(^・ω・^ )`